Salesforce ファイル検索の課題をOCRで解決

Salesforceのグローバル検索で、アップロードしたPDFなどのファイルを検索した際、「ファイル自体は見つかるけれど、そのファイルが紐づいている親レコードが検索結果に出てこない」と困った経験はありませんか?
Salesforceには、ファイルの中身をインデックス化(※)して検索する強力な機能がありますが、標準仕様のままでは業務要件を完全に満たせないケースがあります。
そこで、Google Vision APIの「OCR」技術を活用して検索による課題を解決し、社内の情報アクセスを圧倒的に効率化する画期的なアプローチをご紹介いたします。
※システムがファイル名やコンテンツ(全文)を自動的に読み取り、キーワード検索を可能にする仕組み
はじめに
Salesforce標準検索の「惜しい」仕様
SalesforceでPDFや画像などのファイルをレコードに添付すると、標準の検索機能によってファイル内のテキストが検索対象になります。
しかし、グローバル検索でキーワードを入力した際、ヒットするのはあくまで「ファイル(ContentVersionレコード)」そのものであり、そのファイルが添付されている「取引先」や「カスタムオブジェクト」などの親レコードを直接検索結果に表示させることはできません。
レコードに添付しているPDFに含まれるキーワード「光ファイバー」で検索しても・・・
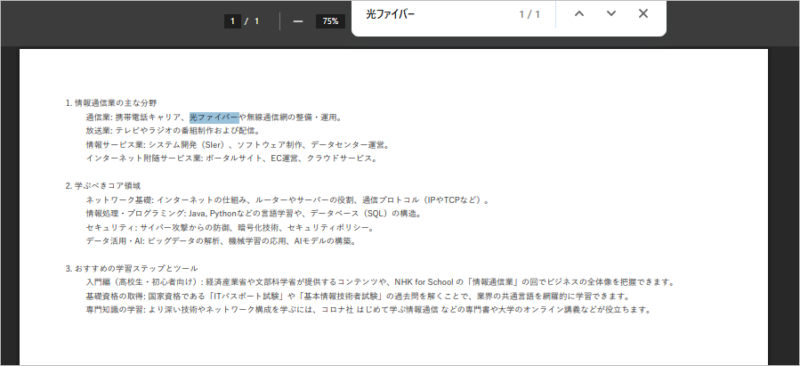
ファイルはヒットするがレコードはヒットしません。
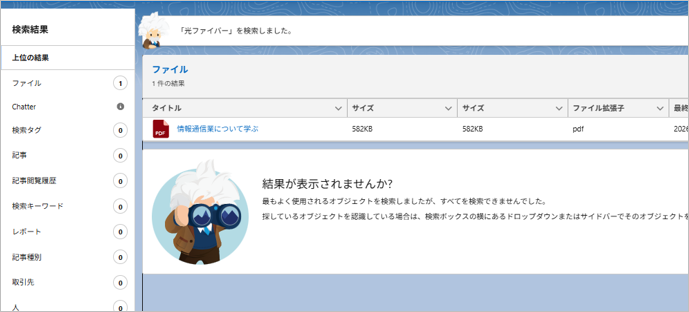
このSalesforceのファイル検索の標準仕様によって、以下のような現場の課題が発生します。
- マニュアルや規約のPDFを検索した際、ファイルだけが表示されても、それがどの製品や契約に紐づくものなのか一目で分からない
- Experience Cloudの検索結果画面から、直接対象の親レコード(詳細画面)に遷移させたいが、標準機能では実現できない
- ファイル名だけでなく、ファイル内の特定の文言で親レコードを絞り込みたい
せっかくファイルの中身が検索できても、業務の起点となる「レコード」にたどり着けないのは非常に惜しいポイントです。
この課題を解決するためには、「ファイルに含まれるテキストを自動で検出し、親レコードの項目に持たせる」という仕組みの構築が必要になります。
本記事では、PDFを添付した場合のこの仕組みの具体的な実装手順を解説していきます。
Google Vision APIとは?
事前に知っておくべきポイント
添付ファイルのテキストを親レコードに持たせるためには、ファイルがレコードに紐づけられたタイミングで中身を読み取る必要があります。そこで活躍するのがOCR(光学式文字認識)です。
今回は、Googleが提供する強力な画像認識・テキスト抽出サービスである「Google Cloud Vision API」を利用します。
Google Vision APIを連携させることで、以下のようなメリットが生まれます。
- テキストベースのPDFだけでなく、スキャンした画像化されたPDFや、JPEG等の画像内の文字も高精度に抽出できる
- 多言語に対応しており、日本語の複雑なレイアウトの文書でも正確にテキストを読み取れる
ただし、外部のOCR APIを利用してファイル検索の機能を拡張するにあたり、事前に知っておくべき重要な注意点が2つあります。
注意点① – コストと制限の把握
Google Vision APIは、毎月一定回数(例:最初の1,000単位など)までは無料で利用できますが、それを超えると従量課金が発生します。
また、一度のAPIリクエストで処理できるファイルサイズやページ数にも上限があるため、大容量のファイルを扱う場合は分割処理などの考慮が必要です。
料金について詳細はGoogleの公式ページを参照してください。
https://cloud.google.com/vision/pricing?hl=ja#prices
注意点② – コンプライアンスとセキュリティ
最も注意すべきはセキュリティ面です。Salesforceにアップロードされた顧客データ、機密情報、個人情報を含むファイルを外部のAPI(Google側)に送信することになります。
そのため、自社のセキュリティポリシーに違反しないか、API側のデータ利用規約(学習データとして利用されないか等)を事前に法務・セキュリティ部門と確認することが必須です。
処理の全体像とSalesforceの仕組み
Salesforceで理想的なファイル検索を実現するために、システム全体でどのような処理を行うのか、その流れを解説します。
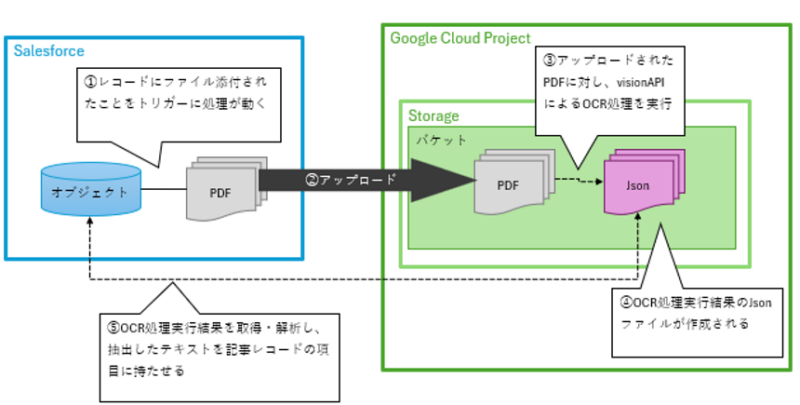
処理 全体像
①ファイルのアップロード
Salesforceの画面から、親レコードにPDFファイルをアップロードします。
これをきっかけに裏側でApexトリガーが自動起動します。
②PDFを一時保管庫へ転送(Salesforce → GCS)
トリガー(非同期処理)が、PDFファイルをGoogle Cloud Storage(GCS)の input フォルダへ転送します。
③Google Cloud プロジェクト へOCRを依頼(Salesforce → Vision API)
SalesforceからVision APIへ、保管したPDFのOCR処理実行を依頼します。
このときVision API(Google側)から発行される「受付番号」を親レコードにメモして、最初の処理は終了します。
④バックグラウンドでOCR実行(プロジェクト内部)
Google Cloud側が裏でPDFを1ページずつ解析します。
完了すると、抽出されたテキストデータ(JSON)がGCSの result フォルダへ自動保存されます。
⑤テキストの回収と保存(Salesforceバッチ)
定期起動するSalesforceのApexバッチが、メモしておいた「受付番号」を元にプロジェクトへ完了確認に行きます。処理が終わっていれば、GCSからテキストデータを読み込んで親レコードの専用項目に自動保存します。
【処理イメージ】
非同期処理の重要性について
この実装において最も重要な技術的ポイントは「非同期処理」です。
Salesforceの仕様(ガバナ制限)により、データベースの更新を伴うApexトリガー処理の中から、直接外部システムへのHTTPコールアウト(通信)を行うことは禁止されています。
そのため、トリガー内から外部APIを呼び出す際は、必ず「@future(callout=true)」アノテーションを付与したメソッド、または「Queueable」インターフェースを利用し、別スレッドの処理としてAPI連携を行う必要があります。
これにより、ユーザーのファイルアップロード操作を邪魔することなく、裏側でシームレスに文字抽出とレコード更新を完了させることができます。
実践
準備フェーズ(Google側/Salesforce側)
ここからは、実際にSalesforce ファイル検索を強化するための実装手順を解説します。まずは下準備のフェーズです。
Google側の準備:Vision APIの有効化
1.Google Cloud プロジェクトを作成
Google Cloud Consoleにログインし、新しいプロジェクトを作成(または既存を選択)します。
作成手順 公式ページ:https://developers.google.com/workspace/guides/create-project?hl=ja
※請求先アカウントを紐づけてプロジェクトの課金を有効にしておく必要があります
2.APIを有効化
「APIとサービス」から必要なサービスを検索し、有効化します。
SalesforceからのOCR処理には、Cloud Vision API / Cloud Storage APIの有効化が必要です
- Cloud Vision API: 画像やPDFのテキスト抽出(OCR)を行うメインのAPI
- Cloud Storage API: SalesforceからPDFをGCSにアップロードし、処理結果のJSONファイルをダウンロードするための通信API
「APIとサービスを有効にする」をクリック
「vision API」を検索、検索結果をクリック
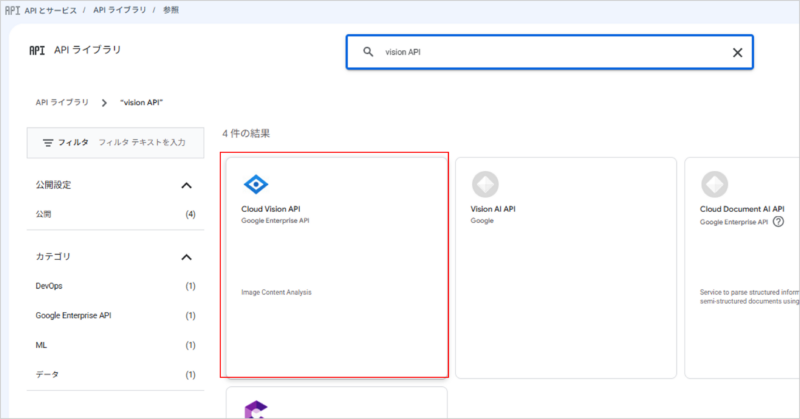
「有効にする」をクリックし、有効化

※Cloud Storage APIも同様の手順で有効化します
3.OAuth 2.0の認証情報を発行
Salesforceの「指定ログイン情報」からGoogle Cloudプロジェクトへアクセスさせるため、OAuth 2.0の認証情報(クライアントIDとクライアントシークレット)を発行します。
【ステップ1:OAuth 同意画面の設定】
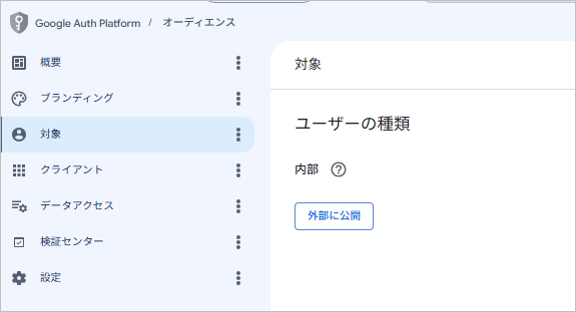
①左メニューの [API とサービス] > [OAuth 同意画面] >[対象]を開き、ユーザータイプを選択(社内ユーザーのみなら「内部」、それ以外は「外部」)します。
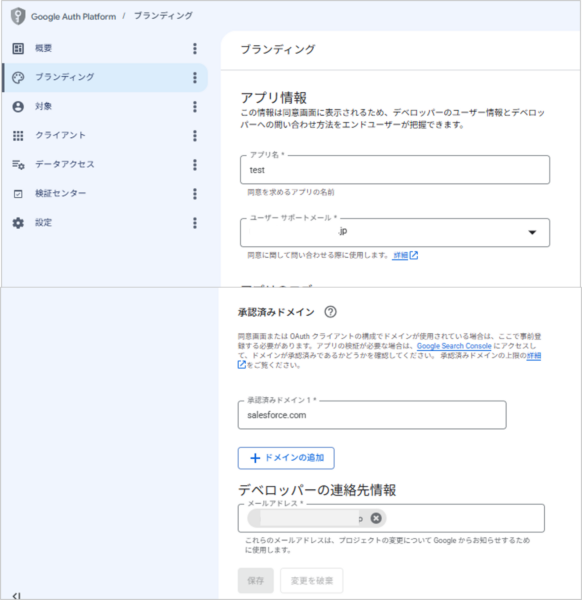
②左メニューの [ブランディング] をクリックし、アプリ名(例:Salesforce OCR Link)やユーザーサポートメールなどの必須項目を入力して保存します。承認済みドメインには、Salesforce組織のドメイン(例:my.salesforce.com や、Experience Cloudで利用しているドメイン)を入力します。
【ステップ2:OAuth 2.0 クライアント ID の発行】
- 引き続き、左メニューの [クライアント] を開きます。
- [+クライアントを作成](または [認証情報を作成] > [OAuth クライアント ID])を選択します。
- アプリケーションの種類で [ウェブ アプリケーション] を選択し、名前を入力します。
- 画面下部にある「承認済みのリダイレクト URI」に、Salesforce側で後ほど発行される「コールバックURL」を入力して作成します。
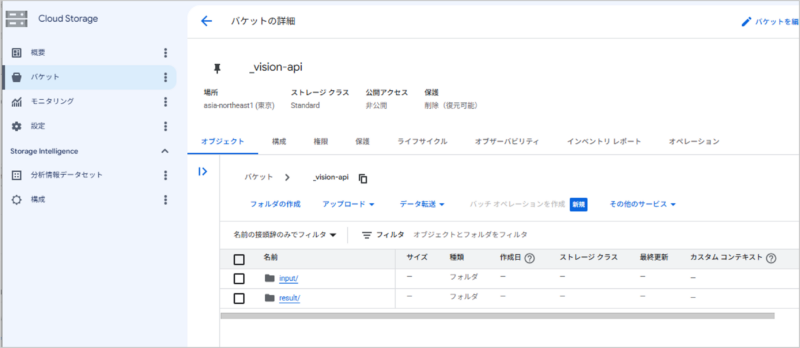
4.Cloud Storageにバケットを作成
Cloud Storage > バケット にSalesforceから受け取る、OCR処理対象ファイルの保管場所を作成します。
バケット
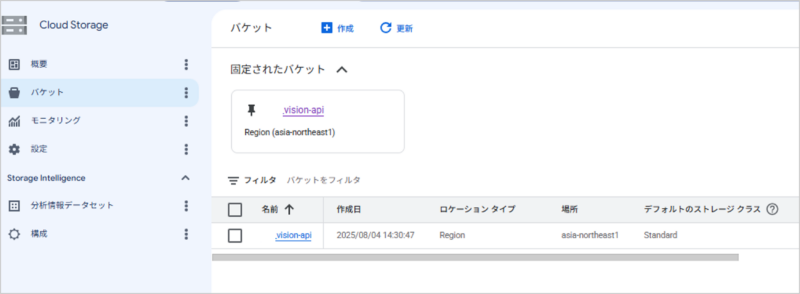
フォルダは2つ作成
- input:OCR処理対象ファイルを受け取るためのフォルダ
- result:inputフォルダに入ってきたファイルをCloud Vision API でOCR処理し、その結果のJsonファイルを格納するフォルダ
Salesforce側の準備:項目作成とセキュリティ設定
1.項目作成
PDFを添付する親オブジェクトに、次の3項目を作成します
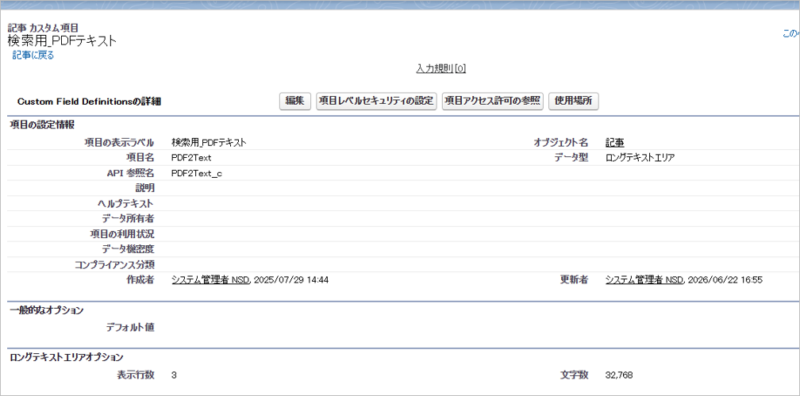
①テキストの保存先を作成(ロングテキストエリア)
PDFから読み取ったテキストの保存先項目を作成します。
画像はカスタムオブジェクトに「検索用_PDFテキスト」として項目を作成
②GCP受付番号(テキスト)
Google CloudプロジェクトにOCRを依頼した際に発行される「受付番号(Operation ID)」を一時的にメモしておくための項目です。
後から起動するバッチ処理は、この番号を元にGoogle Cloud Platform(以下、GCP)へ結果を回収しに行きます。
③OCR処理中フラグ(チェックボックス)
現在OCRの処理待ち、または処理中であることを示すフラグです。
ファイルがアップロードされたらトリガーで True になり、バッチ処理がテキストを回収し終えたら False に戻ります。
2.指定ログイン情報の設定
SalesforceからGoogle Cloud(GCSおよびVision API)へ安全にOAuth 2.0認証で接続するためのセキュリティ設定を行います。これにより、コード内にパスワードやAPIキーを書き込むことなく安全に通信できます。
【ステップ1:認証プロバイダーの作成】
- [設定] > [ID] > [認証プロバイダー] を開き、[新規] をクリックします。
- プロバイダタイプに「Open ID Connect」を選択し、URL名(例:GCP_visionAPI)を入力します。
- Google Cloud側で取得した「クライアントID」と「クライアントシークレット」を以下のように入力して保存します。
- コンシューマー鍵 :クライアントID
- コンシューマーの秘密:クライアントシークレット
- 保存後、画面最下部に表示される「コールバックURL」をコピーし、Google Cloud側の「承認済みのリダイレクトURI」に貼り付けて保存(更新)します。
【ステップ2:外部ログイン情報の作成】
- [設定] > [セキュリティ] > [指定ログイン情報] を開き、[指定ログイン情報] タブから [新規] をクリックします。
- 下記の2つの指定ログイン情報を作成します。
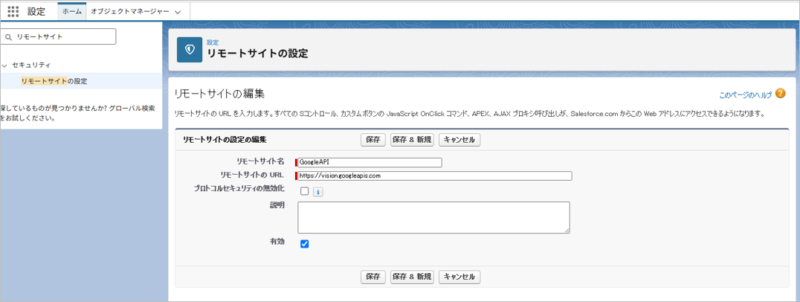
- 名前 :GCP_visionAPI
- URL :https://vision.googleapis.com
- 認証プロトコル:OAuth 2.0
- 認証プロバイダー:ステップ1で作成したものを選択
- 範囲 :https://www.googleapis.com/auth/cloud-platform, https://www.googleapis.com/auth/cloud-vision
- 名前 :GCP_Storage
- URL :https://storage.googleapis.com
- 認証プロトコル:OAuth 2.0
- 認証プロバイダー:ステップ1で作成したものを選択
- 範囲 :https://www.googleapis.com/auth/cloud-platform
- 保存後、画面下部の「プリンシパル」の [新規] をクリックし、任意の名前(例:GCP_Principal)を入力して保存します。
- 作成したプリンシパルの右側にあるアクションメニューから [認証] を実行し、対象のGoogleアカウントでログインしてアクセスを許可します(ステータスが「認証済み」になれば成功です)。
① VisionAPI用
②Google Cloud Storage用
Apex実装フェーズと検索テスト
準備が整ったら、いよいよApexコードによる実装です。
以下は、基本的な処理の流れを示すサンプルコードです。
Apexコールアウトクラスの実装
まずは、Google Vision APIを呼び出す非同期メソッドを作成します。
【Apex:コールアウトクラス】
public class VisionApiPdfOcrService implements Database.Batchable<SObject>, Database.AllowsCallouts {
// カスタム表示ラベルからGCPのバケット名を取得
private static final String BUCKET_NAME = System.Label.GCS_BUCKET_NAME;
// =========================================================================
// 1. トリガーから呼ばれる非同期処理(PDFのGCSアップロード & OCR開始指示)
// =========================================================================
@future(callout=true)
public static void startPdfOcrProcess(Id contentVersionId, Id recordId) {
try {
// 1-1. PDFデータの取得
ContentVersion cv = [SELECT VersionData FROM ContentVersion WHERE Id = :contentVersionId LIMIT 1];
String fileName = 'input/' + contentVersionId + '.pdf';
// 1-2. GCSへPDFをアップロード
HttpRequest uploadReq = new HttpRequest();
uploadReq.setEndpoint('callout:GCP_Storage/upload/storage/v1/b/' + BUCKET_NAME + '/o?uploadType=media&name=' + fileName);
uploadReq.setMethod('POST');
uploadReq.setHeader('Content-Type', 'application/pdf');
uploadReq.setBodyAsBlob(cv.VersionData);
HttpResponse uploadRes = new Http().send(uploadReq);
if (uploadRes.getStatusCode() != 200 && uploadRes.getStatusCode() != 201) {
System.debug('PDFアップロード失敗: ' + uploadRes.getBody());
return;
}
// 1-3. Vision API (asyncBatchAnnotate) へOCR処理をリクエスト
String inputUri = 'gs://' + BUCKET_NAME + '/' + fileName;
String outputUri = 'gs://' + BUCKET_NAME + '/result/' + contentVersionId + '/';
String jsonBody = '{' +
'"requests": [{"inputConfig": {"gcsSource": {"uri": "' + inputUri + '"}, "mimeType": "application/pdf"},' +
'"features": [{"type": "DOCUMENT_TEXT_DETECTION"}],' +
'"outputConfig": {"gcsDestination": {"uri": "' + outputUri + '"}, "batchSize": 5}}]' +
'}';
HttpRequest ocrReq = new HttpRequest();
ocrReq.setEndpoint('callout:GCP_visionAPI/v1/files:asyncBatchAnnotate');
ocrReq.setMethod('POST');
ocrReq.setHeader('Content-Type', 'application/json');
ocrReq.setHeader('x-goog-project-id', System.Label.GCP_PROJECT_ID);
ocrReq.setBody(jsonBody);
HttpResponse ocrRes = new Http().send(ocrReq);
// 1-4. 受付番号(Operation Name)を取得して記事レコードに保存
if (ocrRes.getStatusCode() == 200) {
Map<String, Object> result = (Map<String, Object>) JSON.deserializeUntyped(ocrRes.getBody());
String operationName = ((String)result.get('name')).substringAfterLast('/');
KmShareArticle__c article = new KmShareArticle__c(Id = recordId);
article.operationName__c = contentVersionId + '##' + operationName;
article.isProcess__c = true;
update article;
}
} catch(Exception e) {
System.debug('OCR開始エラー: ' + e.getMessage());
}
}
// =========================================================================
// 2. バッチ処理(OCR完了確認 & テキストのSalesforce保存)
// =========================================================================
public Database.QueryLocator start(Database.BatchableContext bc) {
// 処理中のフラグが立っている記事レコードを抽出
return Database.getQueryLocator([SELECT Id, operationName__c, PDF2Text__c FROM KmShareArticle__c WHERE isProcess__c = true]);
}
public void execute(Database.BatchableContext bc, List<SObject> scope) {
for (SObject s : scope) {
KmShareArticle__c article = (KmShareArticle__c)s;
if (String.isBlank(article.operationName__c)) continue;
// 保存されているIDと受付番号を分割
List<String> parts = article.operationName__c.split('##');
String cvId = parts[0];
String operationName = parts[1];
// 2-1. OCR処理が完了しているか確認
HttpRequest checkReq = new HttpRequest();
checkReq.setEndpoint('callout:GCP_visionAPI/v1/operations/' + operationName);
checkReq.setMethod('GET');
HttpResponse checkRes = new Http().send(checkReq);
if (checkRes.getStatusCode() == 200) {
Map<String, Object> checkBody = (Map<String, Object>) JSON.deserializeUntyped(checkRes.getBody());
Boolean isDone = (Boolean) checkBody.get('done');
// 完了していればGCSから結果JSONを取得して処理
if (isDone == true) {
processCompletedOcr(article, cvId);
}
}
}
}
public void finish(Database.BatchableContext bc) {
System.debug('OCR結果回収バッチ完了');
}
// =========================================================================
// 3. ヘルパーメソッド群
// =========================================================================
// GCSから複数のJSONファイルを取得し、テキストを結合してレコードを更新する
private void processCompletedOcr(KmShareArticle__c article, String cvId) {
String folderPrefix = 'result/' + cvId + '/';
// ① 出力されたファイル名の一覧を動的に取得する
List<String> fileList = listFilesInFolder(folderPrefix);
if (fileList.isEmpty()) {
System.debug('OCR結果ファイルが見つかりません');
return;
}
String extractedText = '';
// ② 取得したファイル一覧をループして、それぞれの中身(テキスト)を抽出
for (String resultFileName : fileList) {
HttpRequest getReq = new HttpRequest();
getReq.setEndpoint('callout:GCP_Storage/storage/v1/b/' + BUCKET_NAME + '/o/' + EncodingUtil.urlEncode(resultFileName, 'UTF-8') + '?alt=media');
getReq.setMethod('GET');
HttpResponse getRes = new Http().send(getReq);
if (getRes.getStatusCode() == 200) {
// Untypedでテキストだけを抜き出す
Map<String, Object> jsonRoot = (Map<String, Object>) JSON.deserializeUntyped(getRes.getBody());
List<Object> responses = (List<Object>) jsonRoot.get('responses');
if (responses != null) {
for (Object resObj : responses) {
Map<String, Object> responseMap = (Map<String, Object>) resObj;
Map<String, Object> fullTextAnnotation = (Map<String, Object>) responseMap.get('fullTextAnnotation');
if (fullTextAnnotation != null) {
extractedText += (String) fullTextAnnotation.get('text') + '\n';
}
}
}
}
}
// ③ すべてのファイルのテキストを結合したら、親レコードを更新
article.PDF2Text__c = (article.PDF2Text__c == null ? '' : article.PDF2Text__c) + extractedText;
article.operationName__c = ''; // 処理完了のためクリア
article.isProcess__c = false;
update article;
}
// GCSの特定フォルダ内のファイル名リストを取得する
private List<String> listFilesInFolder(String folderPrefix) {
List<String> fileList = new List<String>();
HttpRequest req = new HttpRequest();
req.setMethod('GET');
String endpoint = 'callout:GCP_Storage/storage/v1/b/' + BUCKET_NAME + '/o?prefix=' + EncodingUtil.urlEncode(folderPrefix, 'UTF-8');
req.setEndpoint(endpoint);
req.setHeader('Accept', 'application/json');
HttpResponse res = new Http().send(req);
if (res.getStatusCode() == 200) {
Map<String, Object> result = (Map<String, Object>) JSON.deserializeUntyped(res.getBody());
if (result.containsKey('items')) {
List<Object> items = (List<Object>) result.get('items');
for (Object itemObj : items) {
Map<String, Object> item = (Map<String, Object>) itemObj;
fileList.add((String) item.get('name'));
}
}
} else {
System.debug('GCSファイル一覧取得エラー: ' + res.getBody());
}
return fileList;
}
}
Apexトリガーの実装
次に、ファイルがレコードにアップロードされた瞬間に上記のクラスを呼び出すトリガーとトリガーハンドラーを作成します。
【Apexトリガー】
trigger ContentVersionTrigger on ContentVersion (after insert) {
ContentVersionTriggerHandler.handleAfterInsert(Trigger.new);
}
【Apexトリガーハンドラー】
public class ContentVersionTriggerHandler {
public static void handleAfterInsert(List<ContentVersion> newList) {
Set<Id> contentDocumentIds = new Set<Id>();
Map<Id, Id> docIdToVersionIdMap = new Map<Id, Id>();
// 1. アップロードされたファイルの中から「PDF」かつ「最新バージョン」のものを抽出
for(ContentVersion cv : newList){
if(cv.FileType == 'PDF' && cv.IsLatest){
contentDocumentIds.add(cv.ContentDocumentId);
// 後でContentVersionのIDを取り出せるようにMapに保持
docIdToVersionIdMap.put(cv.ContentDocumentId, cv.Id);
}
}
// 対象ファイルがなければここで処理終了
if (contentDocumentIds.isEmpty()) return;
// 2. ファイルが「どのレコード」に紐づいているか(ContentDocumentLink)を取得
List<ContentDocumentLink> links = [
SELECT ContentDocumentId, LinkedEntityId
FROM ContentDocumentLink
WHERE ContentDocumentId IN :contentDocumentIds
];
// 対象となるオブジェクトのプレフィックス(IDの先頭3文字)を取得
String targetPrefix = KmShareArticle__c.SObjectType.getDescribe().getKeyPrefix();
// 3. 紐づき先が対象の指定の親レコードであれば、統合版のOCR処理クラスを呼び出す
for (ContentDocumentLink cdl : links) {
if(String.valueOf(cdl.LinkedEntityId).startsWith(targetPrefix)) {
Id contentVersionId = docIdToVersionIdMap.get(cdl.ContentDocumentId);
Id articleId = cdl.LinkedEntityId;
VisionApiPdfOcrService.startPdfOcrProcess(contentVersionId, articleId);
}
}
}
}
検索テストの実施
上記の実装が完了したら、実際にテストを行います。
【ステップ1:ファイルを親レコードにアップロード】
対象のレコードを開き、「ファイルをアップロード」から検証用のPDFファイルを新しく追加します。これにより裏側でトリガーが自動起動し、GCSへのアップロードとOCRの依頼までが瞬時に完了します。
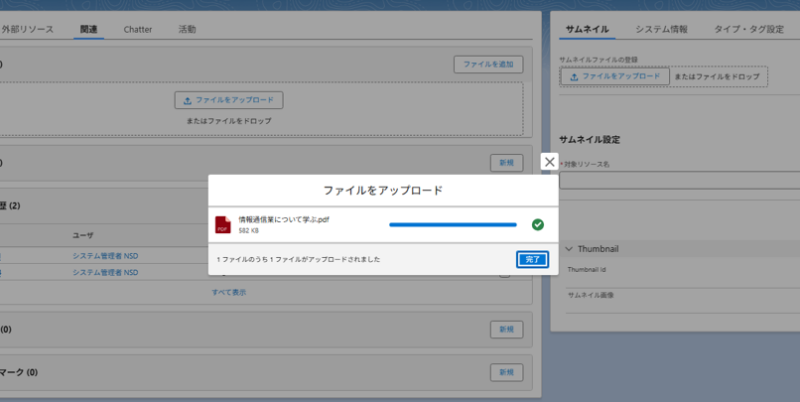
この時、Salesforceではファイルを添付した親レコードの項目「GCP受付番号」と「OCR処理中フラグ」が更新されます。
※ページレイアウトに項目表示していないためインスペクターで確認

【ステップ2:結果回収バッチを「匿名実行」で呼び出す】
Google Cloud側でPDFの解析が行われるのを少し(数ページなら1〜2分程度)待ってから、開発者コンソールの「Execute Anonymous Window(匿名実行ウィンドウ)」を開き、以下のコードを入力して実行(Execute)し、結果を回収するバッチ処理を手動で起動します。
Database.executeBatch(new VisionApiPdfOcrService(), 1);
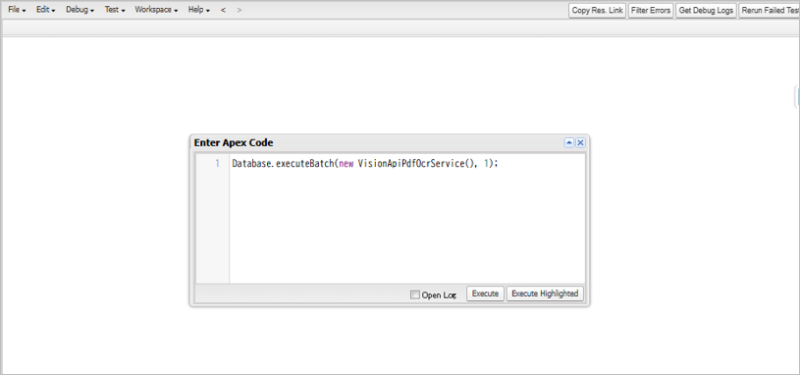
※今回は結果をすぐに確認するために開発者コンソールからバッチを手動で匿名実行しました。実際に本番環境で運用する際は、このバッチクラス(VisionApiPdfOcrService)を「スケジュール済みApex」として登録します 。
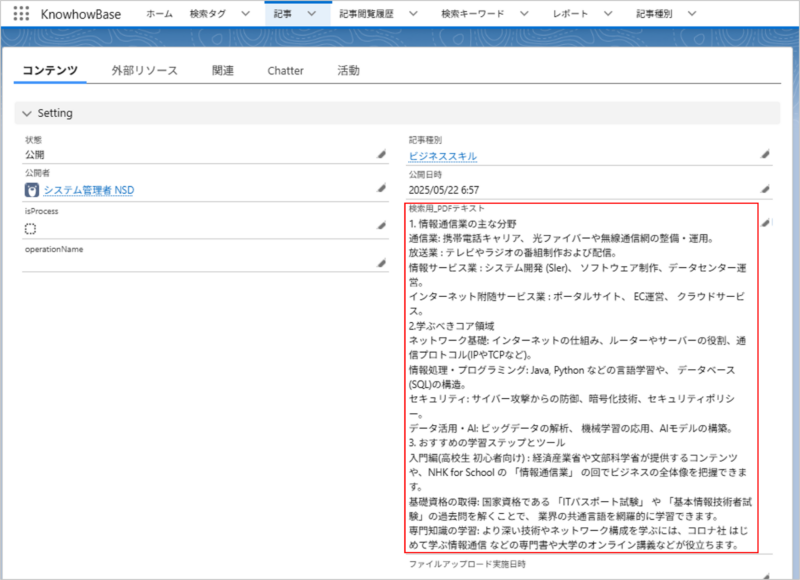
【ステップ3:テキストが保存され、検索可能に】
バッチ処理が完了したあと親レコードの画面をリロードすると、OCR結果テキスト用項目「検索用_PDFテキスト」に文字起こしされたデータが自動で保存されています。
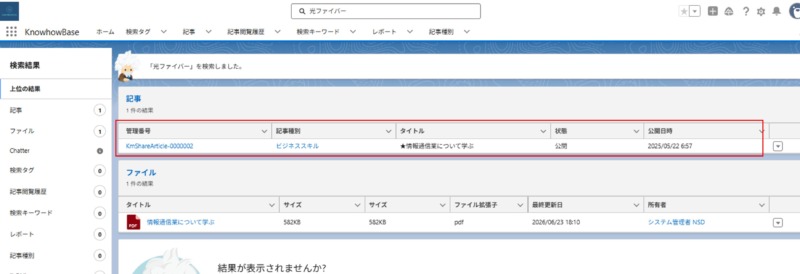
この状態で、グローバル検索でファイル内のキーワードを入力すると、「ファイル」だけでなく「親レコード」そのものが検索結果にヒットして表示されるようになります!
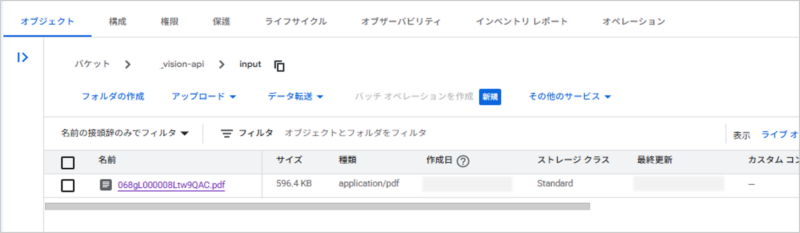
【補足】
GCSのバケットにはSalesforceからアップロードしたPDFとOCR実行結果のJsonファイルが残ります。保管ファイルが増えれば無料分を超えて課金が発生するため、適宜削除してください。
inputフォルダ
resultフォルダ
まとめ
OCR連携で広がるSalesforceの業務改善
本記事では、Salesforce ファイル検索の課題を解決するため、Google Vision API(OCR)を利用してファイル内の文字を抽出し、親レコードを検索対象にする方法をご紹介しました。
非同期処理や外部API連携といった開発要素はありますが、一度この実装の型を作ってしまえば、検索の利便性は劇的に向上します。
さらに、このOCR技術を活用した仕組みは、単なる検索目的以外にも幅広い業務改善へ応用することが可能です。
- 見積書や請求書のPDFをアップロードするだけで、金額や取引先名を自動抽出し、Salesforceのレコード項目へ自動入力する
- ユーザーからアップロードされた画像内に、不適切な表現やNGワードが含まれていないかを自動でチェックする
- 名刺画像を読み込み、そのまま取引先責任者として登録する
外部API連携は一見ハードルが高く感じられるかもしれませんが、Salesforceのプラットフォームの可能性を無限に広げてくれる強力な武器です。
ぜひ本記事を参考に、自社の業務要件に合わせたOCR連携の実装にチャレンジしてみてください!
Salesforceノウハウ共有ツール「KnowhowBase」は‘ノウハウを作る、探す、活用する’をコンセプトに、Salesforceプラットフォーム上で利用できる便利な機能をご提供しています。また、「Salesforce導入サービス」 「Salesforce伴走・開発支援サービス」により、Salesforceを新規導入される方、Salesforceの定着・活用や運用保守・開発を要望される方に合ったサービスもご提案しております。ご興味のある方は、お気軽にお問い合わせください。
当サイトでノウハウ共有やSalesforceの定着促進・保守運用・開発を検討している方へ、様々なダウンロード資料をご用意しております。ぜひ資料をダウンロードいただき、ご活用ください。



